
 English
English 中文
中文 العربية
العربية español
español

Introduction
The AI era is changing one of the most stubborn “constants” in data center operations: the assumption that air is the default heat-removal medium at rack level.
As AI training and inference scale, operators are being pushed toward higher rack power densities, tighter thermal margins at the chip, and more aggressive sustainability commitments—all while lead times, permitting, and grid constraints make it harder to simply build your way out of the problem.
That’s why data center liquid cooling is shifting from “specialty HPC” to mainstream design. The change isn’t only about chasing a better PUE on paper. It’s about keeping AI infrastructure stable under load, avoiding performance throttling, and unlocking capacity without betting the facility on unproven one-off designs.
Standards and ecosystems are also catching up. ASHRAE TC 9.9 guidance continues to evolve for high-density environments (including liquid-cooled IT), and the Open Compute Project (OCP) has active workstreams focused on standardizing cooling components and interfaces—signals that the industry is treating liquid as a long-term platform, not a niche experiment.
For operators, the immediate question is not “air or liquid?” but “what’s the practical path from precision air to liquid—without increasing operational risk?” This article follows that path: drivers, technology options, standards, ROI levers, migration patterns, and reliability controls.
Key Takeaway: Liquid cooling is less about novelty and more about constraints—density, performance stability, and sustainability targets that air alone can’t reliably satisfy at AI scale.
The inevitability drivers
AI densities and throttling
In traditional enterprise compute, air cooling had room to breathe—literally. The limiting factor was often room-level cooling capacity, containment quality, or airflow management. With AI racks, the limiting factor shifts closer to the silicon.
Modern accelerators and dense server designs concentrate heat into smaller footprints. When the heat flux at the die rises faster than airflow can carry it away, you see two costly outcomes:
-
Thermal throttling: performance drops under sustained load to protect the silicon.
-
Fan and airflow escalation: more fan power, higher acoustic/maintenance burden, and a growing share of IT power spent moving air rather than doing compute.
Industry commentary on density trends varies by segment, but the direction is consistent: “high density” is now frequently discussed in the 10–30 kW per rack range, while AI clusters push toward 40–60 kW+ racks depending on architecture and workload (and higher still in some roadmaps). See AFCOM’s discussion in “The Data Center Density Dilemma” (2026) and Ramboll’s overview in “100+ kW per rack in data centers” (2024).
At these levels, “more air” becomes an increasingly inefficient answer:
-
Air has low heat capacity, so you need high volumes and well-controlled paths.
-
Local hotspots don’t average out—GPUs and memory stacks can exceed acceptable temperatures even when aisle conditions look “fine.”
-
The control loop becomes harder: small changes in server population, cable routing, or blanking discipline can create disproportionately large thermal problems.
Liquid changes the physics. You can bring a higher-capacity medium closer to the source (rear-door exchangers, cold plates, or immersion), reduce the dependency on pristine airflow paths, and stabilize chip temperatures across load profiles.
Sustainability and regulations
Sustainability pressure is no longer “nice to have,” especially for operators serving hyperscale and enterprise AI tenants.
A few forces converge:
-
Energy cost and carbon accounting: Scope 2 emissions (grid electricity) can dominate a facility’s footprint. Anything that reduces cooling overhead matters.
-
Regulatory and reporting requirements: regional rules increasingly require energy efficiency transparency and may constrain refrigerant choices, water use, or heat rejection methods.
-
Stakeholder expectations: ESG commitments turn into RFP requirements and audit questions.
Liquid cooling doesn’t automatically make a data center sustainable, but it can unlock operating modes that are difficult with air at high density:
-
Lower fan power at the server level.
-
Higher coolant supply temperatures, which expand economizer hours.
-
More efficient heat rejection with reduced mechanical cooling, depending on climate and architecture.
That matters because the AI load itself is unforgiving: you can’t “schedule” an LLM training run around heat waves or utility peaks without business impact.
Space, capacity, and time-to-market
If you manage a mixed estate, you already know the real-world constraint: you rarely have the luxury of a blank sheet.
Even when capital is available, operators hit bottlenecks:
-
Grid and substation capacity: power delivery upgrades can be the longest pole.
-
Real estate limits: sites with good fiber and power access are scarce.
-
Supply chain and lead times: chillers, switchgear, and generators can be long-lead.
-
Permitting and commissioning: high-density projects face more scrutiny and more integration complexity.
Liquid cooling can act as a capacity unlock. By improving heat removal where it matters (at or near the rack), you reduce the need to oversize room-level air systems and can densify specific zones without rebuilding the entire mechanical plant.
In other words, liquid cooling isn’t only an efficiency move—it’s a time-to-market strategy for AI deployments.
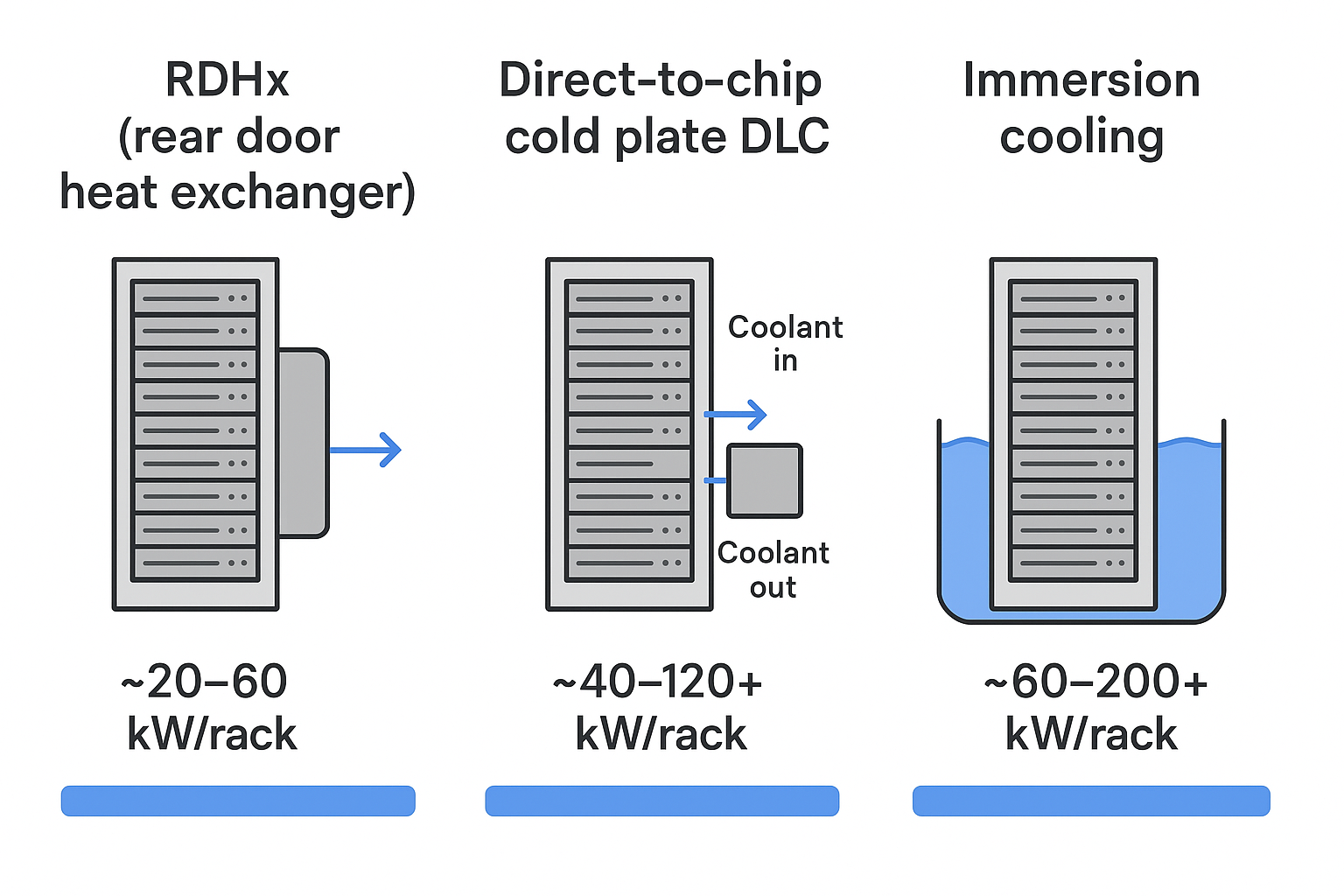
Cooling technologies today
Liquid cooling is not one thing. Operators typically adopt it in stages, based on how quickly they need relief, how dense the racks are, and how much change the facility can tolerate.
RDHx for fast relief
A rear door heat exchanger (RDHx) mounts a liquid-to-air heat exchanger on the rear of the rack. Hot exhaust air passes through the door, transferring heat to a liquid loop.
Why it’s often a first step:
-
Minimal server-level changes compared to cold plates or immersion.
-
Helps relieve hot aisle temperatures and reduce room cooling load.
-
Works well in hybrid environments where many racks remain air cooled.
Common realities to plan for:
-
RDHx performance depends on airflow and pressure drop—fan curves and containment still matter.
-
You introduce liquid connections at the rack level, so you need leakage management and service procedures.
-
A portion of heat remains in air paths unless the door captures most of it.
OCP’s focus on standardizing RDHx interfaces and integration in Open Rack environments is a useful signal that RDHx is becoming more repeatable at scale (see the OCP Door Heat Exchanger project).
Direct-to-chip cold plates
Direct-to-chip cooling uses cold plates mounted on high-heat components (typically GPUs and CPUs). Coolant flows through the plates and carries heat into a liquid loop.
Why it scales for AI:
-
It targets the actual limiting component: the accelerator.
-
It reduces reliance on high-velocity airflow and can substantially reduce fan energy.
-
It supports higher rack densities with more predictable thermal behavior.
Operator considerations:
-
Serviceability changes (quick disconnects, dripless couplings, maintenance procedures).
-
A mixed approach is common: cold plates on GPUs/CPUs while other components remain air cooled.
-
You need clear boundaries between facility water and the technology cooling loop—this is where a Coolant Distribution Unit (CDU) becomes central.
Immersion for peak density
Immersion cooling places servers (or server boards) into a dielectric fluid bath. Heat transfers directly into the fluid, which is then cooled via a heat exchanger.
Why it’s compelling:
-
Very high heat transfer capability.
-
Fan removal becomes possible (depending on design), cutting a source of energy use and failure points.
-
Thermal uniformity can be excellent when engineered well.
Trade-offs operators must weigh:
-
Hardware compatibility and vendor support (not all server platforms are immersion-ready).
-
Operational changes: handling fluid, maintenance workflows, and safety training.
-
Integration complexity at scale: logistics, spares, and standardized processes.
Standards and architectures
Liquid cooling becomes “inevitable” only when it becomes repeatable—and repeatability comes from standards, reference architectures, and operational discipline.
ASHRAE W-classes and TCS
ASHRAE TC 9.9 resources are widely used by operators and OEMs to align on environmental envelopes and safe operating practices.
In liquid-cooled environments, it’s useful to separate:
-
Facility Water System (FWS): site-side water loops, heat rejection, treatment, and plant constraints.
-
Technology Cooling System (TCS): the IT-facing loop feeding racks, cold plates, or immersion systems.
This separation matters because the requirements aren’t identical. The IT-facing loop often needs tighter control on temperature stability, cleanliness, and material compatibility than a typical facility loop.
A practical operator rule: design the TCS as if it were part of the IT system—not “just plumbing.” That’s how you avoid the most common reliability traps.
CDUs, loops, and materials
A CDU (Coolant Distribution Unit) is the boundary device that lets you scale liquid cooling without letting facility complexity leak into the rack.
At a high level, a CDU typically provides:
-
A heat exchanger between facility water and the technology cooling loop
-
Pumps and pressure control on the technology loop
-
Filtration and fluid quality management hooks
-
Control logic for supply temperature, flow, and alarms
Material compatibility is not a footnote. As OCP workstreams note for RDHx systems, corrosion risks and coolant compatibility are first-class design concerns—especially as the ecosystem explores different heat exchanger materials and coatings (see OCP’s project scope in the Door Heat Exchanger wiki).
Controls and monitoring
Liquid cooling is operationally manageable when it’s observable.
The control and monitoring stack should answer, in real time:
-
Are flows and ΔT where they should be per rack and per loop?
-
Is any loop drifting toward condensation risk (dew point margin)?
-
Are filters loading, pumps cavitating, or valves hunting?
-
Are leak sensors and shutoff mechanisms healthy?
Just as importantly, monitoring must integrate with existing operational tooling (DCIM/BMS) so liquid doesn’t become a separate “shadow system.” This is a common objection in enterprise deployments, and it’s solvable with thoughtful interface design.
ROI and efficiency model
Liquid cooling ROI is easy to oversimplify. A good model acknowledges that value comes from multiple levers—some energy-related, some performance-related, and some capacity-related.
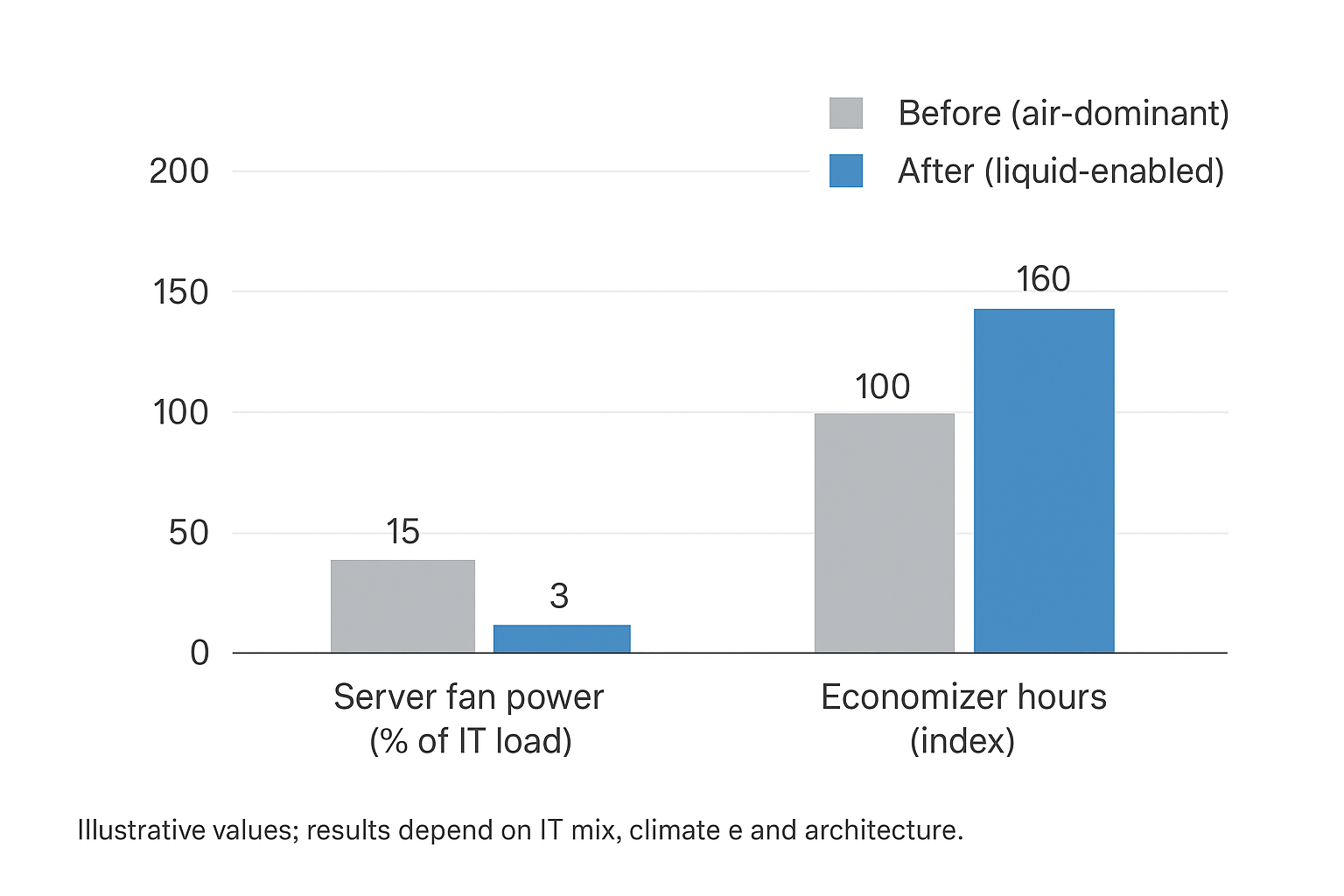
Energy and economization
The most direct efficiency levers tend to be:
-
Reduced server fan energy (because less heat is handled by high-velocity air).
-
Higher supply temperatures on the liquid side, which can expand economizer hours and reduce compressor runtime.
For operators, the point isn’t “liquid is always cheaper.” It’s that liquid expands your feasible operating envelope without sacrificing compute stability.
Performance and consolidation
If air cooling causes throttling at peak load, the energy story is only half the problem.
Stable temperatures can translate into:
-
More consistent AI training time
-
Better utilization of expensive accelerators
-
Fewer “mystery” performance incidents tied to hot spots
On the facility side, liquid cooling can enable consolidation by allowing more compute per footprint—sometimes the dominant ROI lever when space or power delivery is constrained.
Water strategy and WUE
Water usage is increasingly scrutinized, and cooling strategy affects WUE (Water Usage Effectiveness).
In broad terms:
-
Some economizer strategies rely on evaporative heat rejection, improving energy performance but increasing water consumption.
-
Higher-temperature liquid loops can expand dry-cooler viability in more climates, potentially reducing water dependence.
There’s no universal answer. What matters is modeling your climate, heat rejection approach, and reporting requirements.
Migration and retrofit paths
Most operators won’t jump from “precision air everywhere” to “immersion everywhere.” The practical path is staged, risk-managed, and often hybrid for years.
Start with mixed environments
A mixed environment strategy recognizes two realities:
-
Your estate likely has multiple rack classes (legacy, general-purpose, high-density, AI).
-
Operational maturity matters as much as mechanical capability.
Common first steps:
-
Deploy RDHx on targeted rows where exhaust temperatures are the limiting factor.
-
Introduce facility-side loops and distribution sized for a pilot, but architected to scale.
-
Use clear physical and procedural segmentation: liquid-ready rows, defined service windows, and standardized connection practices.
The goal is to build the operational muscle—procedures, alarms, maintenance discipline—before you scale.
Pilot DLC pods for AI
When AI demand is clear, a focused pilot is often the fastest way to de-risk direct-to-chip cooling.
A good pilot does three things:
-
Proves thermal performance under real workloads, not synthetic tests.
-
Validates operations: maintenance, quick disconnect handling, spare parts strategy.
-
Creates repeatable design patterns: piping, containment, controls, and documentation.
Many operators use a “pod” model: isolate a liquid-cooled AI zone with clear boundaries (mechanical, electrical, and operational). This keeps the blast radius small while you learn.
In this context, integrated building blocks can reduce integration risk—as long as they remain interoperable with your existing stack. For example, an integrated CDU paired with monitoring can simplify commissioning by keeping flow/temperature control, alarms, and trend data consistent across racks. Similarly, modular liquid-ready pods can help standardize repeatable deployment units (row, pod, container) rather than redesigning each site. As a reference point, Coolnet publishes background on CDUs in Coolant Distribution Units (CDU) for data center cooling and on modular/integrated approaches in its data center integrated solution overview.
Commissioning and training
Liquid cooling succeeds operationally when commissioning and training are treated as core scope, not project leftovers.
Commissioning best practices typically include:
-
Loop flushing and filtration validation
-
Flow and ΔT verification at the rack level
-
Dew point and condensation margin checks
-
Alarm testing: leak sensors, pump failover, valve actuation
-
Runbooks for common events (QD swap, leak alarm, pump fault)
Training should cover both routine procedures and “rare but high-stakes” events:
-
How to respond to leak alarms without improvisation
-
What changes are allowed in the rack (and what requires approval)
-
How to interpret trends (slow leaks, filter loading, pump wear)
If you do one thing differently than air cooling projects: invest early in making the system observable and trainable. That’s the difference between a one-off pilot and a scalable operating model.
Risk and reliability
Liquid cooling changes failure modes. It doesn’t have to reduce reliability—but you must design and operate around new risks.
Leak detection and safety
Leak management is as much about “small and early” as it is about “big and catastrophic.” Best practice patterns include:
-
Continuous leak detection at racks, manifolds, and CDU interfaces
-
Dripless quick disconnects and disciplined service procedures
-
Clear shutoff zoning so an event isolates a small section, not an entire hall
Safety also includes condensation control. Operators should monitor dew point margin and avoid supply temperatures that create condensation risk on cold surfaces.
Redundancy schemas
Liquid systems typically need explicit redundancy choices:
-
N+1 pump redundancy at the CDU and/or distribution level
-
Fail-safe valve behavior on power loss
-
Dual-path distribution for critical rows (where justified)
The most important redundancy principle is operational: ensure that failover modes are tested and that alarms are actionable.
Interoperability in practice
Interoperability is where many pilots stumble. The risk is not only “vendor lock-in”—it’s tooling fragmentation.
A practical interoperability checklist includes:
-
Standard protocols for telemetry and alarms (to integrate into existing DCIM/BMS)
-
Documented interfaces and connection standards at the rack
-
Clear ownership between facilities and IT teams
OCP’s emphasis on standardized interfaces and integration for RDHx systems exists for a reason: at scale, repeatability beats bespoke engineering. The more your liquid architecture can align with ecosystem patterns and published guidance, the easier it is to sustain across sites.
Conclusion
Liquid cooling is now a practical necessity for AI workloads—not because it’s trendy, but because it addresses the constraints operators can’t ignore: sustained high densities, performance stability, and tightening sustainability targets.
The safest path forward is standards-based and staged:
-
Start with technologies that match your current constraints (RDHx for relief, direct-to-chip for AI zones, immersion where it truly fits).
-
Use reference architectures and well-defined loop boundaries (facility water vs. technology cooling).
-
Build an ROI case that balances energy, capacity, and water strategy—not just one headline metric.
Most importantly: treat liquid cooling as an operating model. With the right monitoring, commissioning discipline, and training, it becomes repeatable—and once it’s repeatable, it becomes inevitable.




 IPv6 network supported
IPv6 network supported